- 1 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:41:46.672 ID:F/llZ8Ur0
- 採点してくれ
- 2 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:42:12.646 ID:ElL6+eM80
- 成果物をZIPで送ってくれ
- 3 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:42:19.929 ID:F/llZ8Ur0
- ちなpython
- 4 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:42:44.896 ID:F/llZ8Ur0
- from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from time import sleep
import csvHEADER = ['動画タイトル','再生時間', '画像URL', '動画ページURL','画質', '閲覧数', '投稿日', '高評価率']
browser = webdriver.Chrome(ChromeDriverManager().install())
#検索キーワードを入力
keyword = 'おっぱい'
#検索開始ページ
page = 1
#検索するページ数
max_page = 100def get_url(keyword,page=1):
url = 'https://www.tokyomotion.net/search?search_query={}&search_type=videos&type=public&page={}'.format(keyword,page)
return urlif __name__ == "__main__":
while page <= 100:
url = get_url(keyword,page)
browser.get(url)
contents = browser.find_elements_by_class_name('col-sm-4.col-md-3.col-lg-3')with open('motion.csv', 'a', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(HEADER)for content in contents:
title = content.find_element_by_class_name('video-title')
time = content.find_element_by_class_name('duration')
post_date = content.find_element_by_class_name('video-added')
views = content.find_element_by_class_name('video-views')
heart = content.find_element_by_class_name('video-rating')
heart_count = heart.find_element_by_tag_name('b')
image = content.find_element_by_class_name('img-responsive ').get_attribute('src')
link = content.find_element_by_class_name('thumb-popu').get_attribute('href')
try:
content.find_element_by_class_name('hd-text-icon')
quality = 'HD'
except:
quality = 'SD'title_csv = title.text
time_csv = time.text
image_csv = image
link_csv = link
quality_csv = quality
pv_csv = views.text
date_csv = post_date.text
evaluation_csv = heart_count.textrow = [title_csv,time_csv,image_csv,link_csv,quality_csv,pv_csv,date_csv,evaluation_csv]
writer.writerow(row)sleep(10)
page += 1 - 13 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:52:10.560 ID:U3MR66nv0
- >>4
これ改行多すぎ規制にならないんだ - 5 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:45:02.239 ID:F/llZ8Ur0
- https://qiita.com/kawamasa/items/730969d164a6ab6d90c8
↑を参考にしてExcelでサムネイル込みで一気に閲覧できるからストレスフリーだぜ!
※画像読み込みまでかなりじかんかかるけど - 6 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:45:35.438 ID:kMaQ51gG0
- >>5
ストレスだらけじゃん - 8 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:46:15.526 ID:F/llZ8Ur0
- >>5
ページめくりの必要がないからストレスフリーなの! - 7 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:45:45.070 ID:F/llZ8Ur0
- ソースコード渡すのに適した方法無いのかな
- 24 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:13:00.542 ID:GhxgIAyf0
- >>7
git hub - 9 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:47:00.561 ID:LrfyGc/q0
- おっpython
- 10 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:47:26.356 ID:cPZA0k65a
- 出来上がるまでに何回抜いた?
- 17 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:57:03.377 ID:F/llZ8Ur0
- >>10
我慢したよ!これから抜く! - 11 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:47:39.527 ID:F/llZ8Ur0
- インデントがおかしいどう渡せばいいんだ
- 12 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:51:21.656 ID:dgkWUCi8M
- ノートン先生大激怒
- 14 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:54:31.605 ID:F/llZ8Ur0
- こんな風に一覧表示できるの
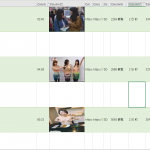
- 15 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:54:43.806 ID:qwCtNHGb0
- 配列rowに入れる値を一旦変数にする必要なくないか?
- 16 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:56:23.421 ID:F/llZ8Ur0
- >>15
こういう意見マジ助かる
調べながらやってると無駄な事に気付かないもんだな…。
修正してくる - 18 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:57:04.821 ID:nI1e+p0k0
- pythonで実行すればいいの?
- 20 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:00:56.230 ID:F/llZ8Ur0
- >>18
そうわよ!
そうすると同じディレクトリにCSVファイルが作られるからそのファイルをExcelとかで開くとシコりやすい - 19 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 16:59:36.721 ID:F/llZ8Ur0
- from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from time import sleep
import csvHEADER = ['動画タイトル','再生時間', '画像URL', '動画ページURL','画質', '閲覧数', '投稿日', '高評価率']
browser = webdriver.Chrome(ChromeDriverManager().install())
#検索キーワードを入力
keyword = 'おっぱい'
#検索開始ページ
page = 1
#検索するページ数
max_page = 100def get_url(keyword,page=1):
url = 'https://www.tokyomotion.net/search?search_query={}&search_type=videos&type=public&page={}'.format(keyword,page)
return urlif __name__ == "__main__":
while page <= 3:
url = get_url(keyword,page)
browser.get(url)
contents = browser.find_elements_by_class_name('col-sm-4.col-md-3.col-lg-3')with open('motion1.csv', 'a', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(HEADER)for content in contents:
title = content.find_element_by_class_name('video-title').text
time = content.find_element_by_class_name('duration').text
date = content.find_element_by_class_name('video-added').text
views = content.find_element_by_class_name('video-views').text
heart = content.find_element_by_class_name('video-rating')
heart_count = heart.find_element_by_tag_name('b').text
image = content.find_element_by_class_name('img-responsive ').get_attribute('src')
link = content.find_element_by_class_name('thumb-popu').get_attribute('href')
try:
content.find_element_by_class_name('hd-text-icon')
quality = 'HD'
except:
quality = 'SD'row = [title,time,image,link,quality,views,date,heart_count]
writer.writerow(row)sleep(10)
page += 1
修正したわよ! - 21 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:02:29.742 ID:F/llZ8Ur0
- 間違えた
- 22 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:04:48.450 ID:F/llZ8Ur0
- from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from time import sleep
import csvHEADER = ['動画タイトル','再生時間', '画像URL', '動画ページURL','画質', '閲覧数', '投稿日', '高評価率']
browser = webdriver.Chrome(ChromeDriverManager().install())
#検索キーワードを入力
keyword = 'おっぱい'#検索開始ページ
page = 1#検索するページ数
max_page = 1#保存するCSVファイル名
save_csv = 'motion8.csv'def get_url(keyword,page=1):
url = 'https://www.tokyomotion.net/search?search_query={}&search_type=videos&type=public&page={}'.format(keyword,page)
return urlif __name__ == "__main__":
while page <= max_page:
url = get_url(keyword,page)
browser.get(url)
contents = browser.find_elements_by_class_name('col-sm-4.col-md-3.col-lg-3')with open(save_csv, 'a', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(HEADER)for content in contents:
title = content.find_element_by_class_name('video-title').text
time = content.find_element_by_class_name('duration').text
date = content.find_element_by_class_name('video-added').text
views = content.find_element_by_class_name('video-views').text
heart = content.find_element_by_class_name('video-rating')
heart_count = heart.find_element_by_tag_name('b').text
image = content.find_element_by_class_name('img-responsive ').get_attribute('src')
link = content.find_element_by_class_name('thumb-popu').get_attribute('href')
try:
content.find_element_by_class_name('hd-text-icon')
quality = 'HD'
except:
quality = 'SD'row = [title,time,image,link,quality,views,date,heart_count]
writer.writerow(row)sleep(10)
page += 1 - 23 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:09:02.091 ID:F/llZ8Ur0
- 使い方GIF作るわ
- 25 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:16:50.790 ID:K3dFmyof0
- 偽計業務妨害
- 26 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:51:48.410 ID:F/llZ8Ur0
- こんな感じに使うかんじ
- 27 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:55:31.792 ID:F/llZ8Ur0
- >>26
実際は滅茶苦茶時間かかる - 38 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:54:36.064 ID:F/llZ8Ur0
- githubスゴイ!独学にピッタリやん!
でも匿名じゃないからとりあえずパイソンファイルうpろだにアップした
https://dotup.org/uploda/dotup.org2534669.py.html>>26
みたいにテキストエディタとかで検索ワードとCSV名を設定してから使ってみて - 28 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:57:33.139 ID:5Qh6ebrEa
- ストレスマッハじゃん
- 29 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 17:58:18.809 ID:F/llZ8Ur0
- >>28
ページめくるストレスがないの! - 30 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:01:16.768 ID:EcAK6Gsj0
- ページめくるワクワク感がないのか
- 31 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:04:06.190 ID:F/llZ8Ur0
- >>30
別にワクワクしないでしょ! - 32 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:04:23.791 ID:SuJ11wTNa
- 別にストレスたまらないでしょ
- 34 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:06:00.388 ID:F/llZ8Ur0
- >>32
僕はたまります - 33 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:04:45.098 ID:F/llZ8Ur0
- スクレイピングはそれなりにできるようになった気がするから次は何の勉強しよう
- 35 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:22:04.645 ID:F/llZ8Ur0
- 誰か使った人いる???
- 36 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:40:35.864 ID:s2Vhq4FAH
- githubに上げといて
- 37 名前:匿名のゴリラ 投稿日時:2021/07/14(水) 18:42:40.452 ID:F/llZ8Ur0
- >>36
よくわからんけどやって見るん
少し前にお前らに相談したエ口サイトのスクレイピングプログラムできたぞ!
 VIP
VIP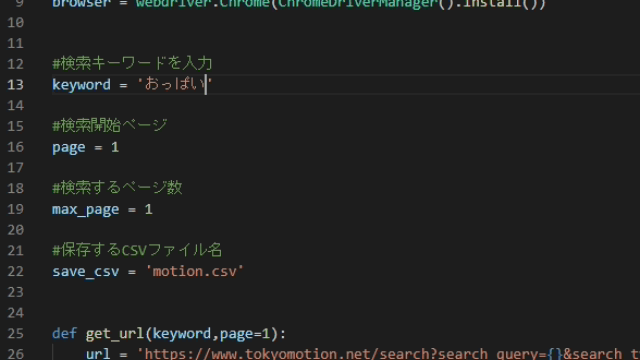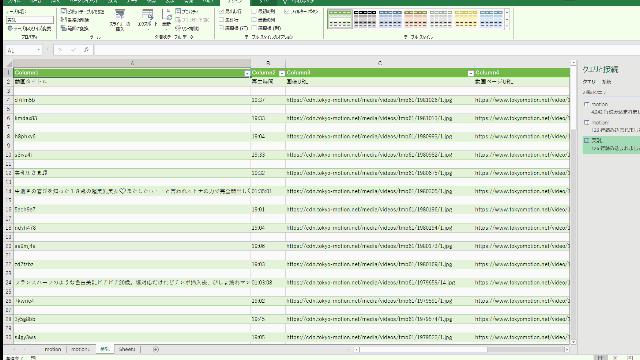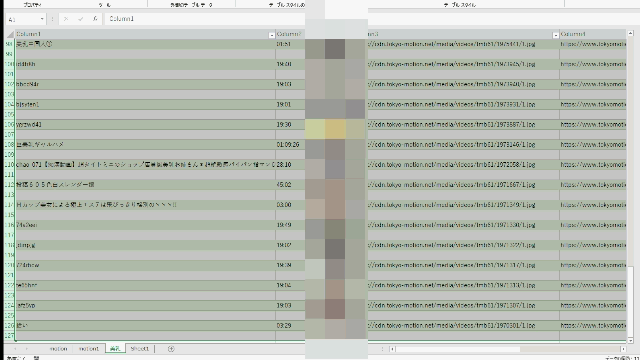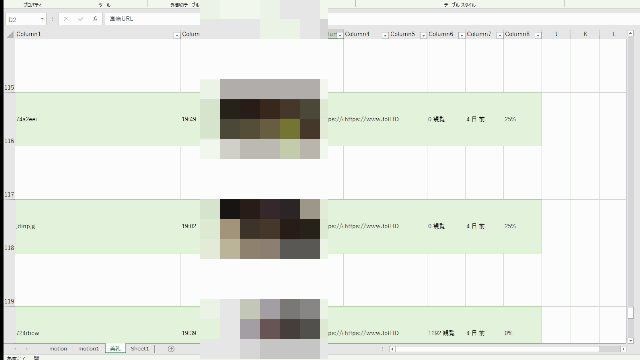

コメント一覧